Hi, I'm Michael
I also develop full-stack applications, APIs, and automation tools, enabling end-to-end solutions from backend systems to user-facing interfaces. Background in scientific research informs a rigorous approach to data quality, analysis, and technical communication.

Formal Education (education-list)
Key Job Experience
Research Assistant (Biophysics)
Florida State University
- Designed a framework to read a variety of structured and unstructured protein databases using Python, Pyspark (from Apache Spark) to enable us to make side-by-side comparisons of how other labs study how proteins move, and thereby test the effectiveness of our own methods.
- Used framework to pipeline protein data where it was queried in Spark-SQL, enabling rapid performance on large datasets.
- Ensured code quality with pre-commit, black, isort, flake8 and Github Actions
- Wrote Python libraries for serializing/deserializing PDB files and transforming protein data as Pandas Dataframes, enabling other teams to work with protein data in an analytics-friendly format (such as Apache Parquet).
- Presented research finding to department faculty in the form of a public lecture.
Software Developer
Anju Software, Inc.
- Built and Maintained data pipelines in Azure Databricks, and Unity Catalog and data modeling principles to transform raw data from clinical trials (collected through our software) into easily accessed data marts and reports that enable our clients to make effective decisions about ongoing drug trial design.
- Developed and orchestrated the above pipelines with Airflow and dbt for large-scale client datasets, using templated SQL and incremental loading strategies to improve data delivery timeliness, reliability, and traceability.
- Investigated and corrected source-code defects for clinical data-entry software written in C# and Microsoft SQL (tSQL), and wrote performance-optimized queries to safely fix any bad data generated through bugs or through user error.
- Debug codebase software in C# and tSQL to identify and fix problems in product
- Automated development environment setup using Docker, Git, and GitHub CI/CD workflows, improving deployment consistency and reducing onboarding and integration time across teams.
Software Developer
Anju Software, Inc.
- Led development of a centralized data warehouse and performance-optimized SQL reporting workflows, improving data accessibility and reducing report generation time for business operations.
- Gathered business requirements and designed operational reports used daily by management teams to prioritize workloads and support decision-making.
- Collaborated with technical and non-technical stakeholders to translate operational needs into reporting and data solutions, improving adoption and cross-team communication.
- Analyzed structured and unstructured lead generation data to identify high-conversion contact patterns, improving targeting efficiency and optimizing outbound call campaigns.
- Built and maintained REST API data ingestion pipelines to integrate new lead sources, expanding available business intelligence data and improving pipeline reliability.
A selection of my work
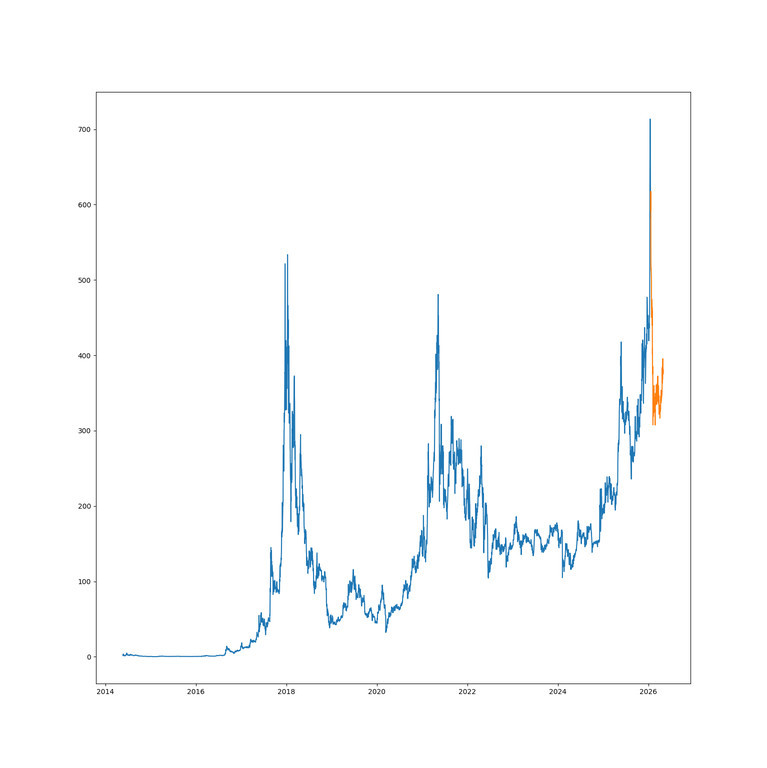
Cryptocurrency Tracker
After recent success in the cryptocurrency market. I decided to build an efficient cryptocurrency tracker. It grabs the latest prices for any and all cryptocurrencis that the user defines. Here are a few features:
- An alerting sytem, that lets you know when a currency’s price has moved out of preset bounds, or if a currency’s price has changed by more than a given percentage in a given time.
- Graph price history of a currency in USD
- Graph price history of a currency relative to another currency BTC/GOLD
- “Last at” queries, which enable you to see at a glance when a currency was, if ever, at a given price.
Molecular DataBase (a Protein Conformational Pipeline)
The lab where I worked at FSU was studying protein dynamis - the ways that proteins move in order to do their particular functions. This has been studied by many others. But when each research group database of protein movements, they change the definition of what kind of movement is taking place.
In order to make possible a cross-comparison of conformational studies I created a unified data pipeline capable of injesting data from:
- html formats for DynDom and Protein Structual Change (PSC) databases
- Protein Data Bank api json results
- SCOPe categorization database custom file formats
Once this data was gathered, PySpark transformed it into tables which could be queried with ordinary SQL, enabling easy cross-comparison of databases. One of the most advanced features of this code is the of subclasses and graphlib to handle recursive dependencies, which is a particular issue with the Protein Data Bank.
Clioreader
Clioreader is a full-stack web application using Flask, BootStrap, and Amazon Web Services to enable a user to upload text, including pdf format books, and convert them into audiobooks using Amazon’s state-of-the-art Text-To-Speech engine.
(not actively maintained)
What you seek
If you are looking for someone to take care of any of the following needs, I may just be the right person for you.
- Data Warehouse or Pipeline Development and Maintenance
- Analytics using databases
- Web Application development
- REST API development
- Static Web site development and deployment